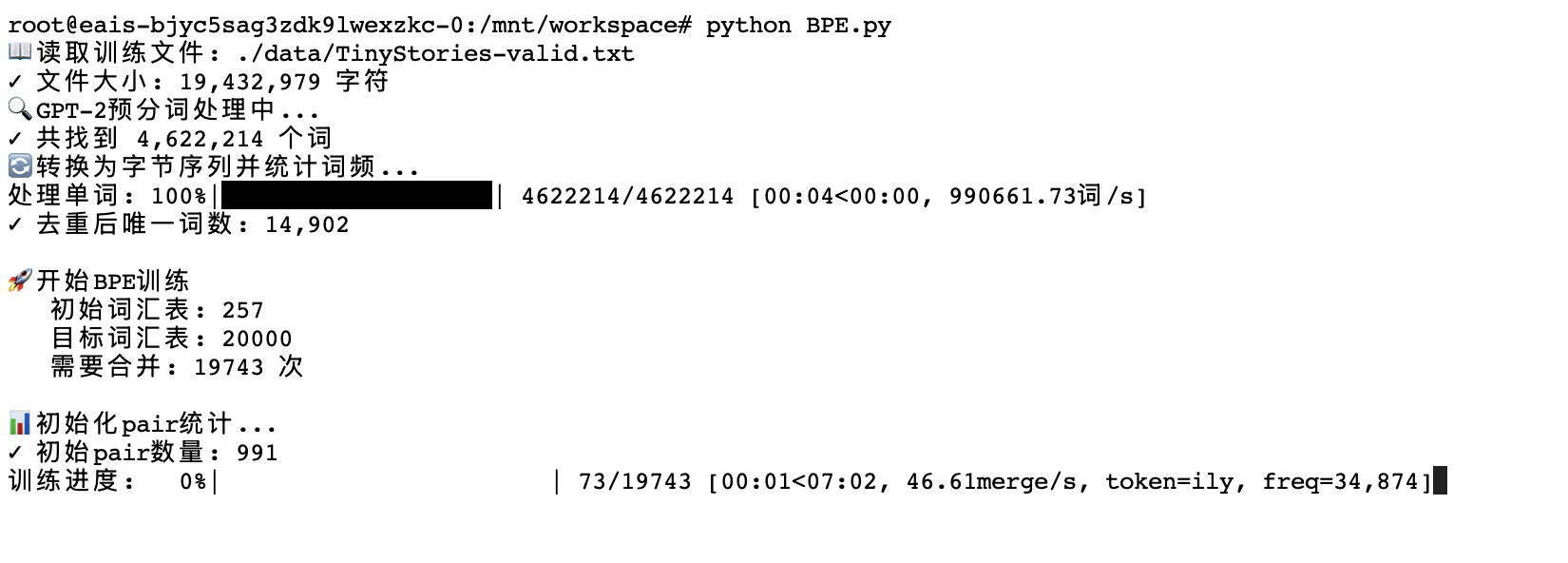
问题背景
原始 BPE 训练速度:0.08 merge/s(12.6 秒/merge),预计需要 69 小时完成训练 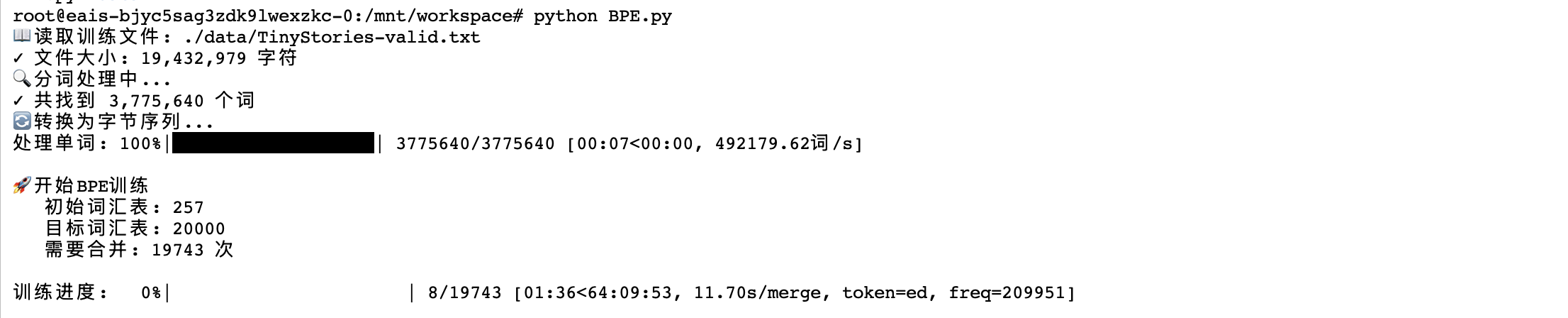
核心优化思路
从"处理所有实例"到"处理唯一模式+频率" - 经典的空间换时间策略
- 词频字典代替序列列表: 存储量从 100 万 → 3 万
优化前
sequences: List[List[str]] = [] # 存储100万个单词序列
for word in words:
sequences.append([tokens...]) # 每个重复词都存一遍
优化后
word_freqs: Dict[Tuple[str, ...], int] = {} # 只存唯一词+频率
for word in words:
word_tokens = tuple([tokens...])
word_freqs[word_tokens] = word_freqs.get(word_tokens, 0) + 1
- 频率加权统计:统计速度提升 30-40 倍
优化前
def get_stats(sequences):
for seq in sequences: # 遍历100万次
for i in range(len(seq) - 1):
pairs[pair] += 1 # 每个"the"都累加一次
优化后
def get_stats(word_freqs):
for word, freq in word_freqs.items(): # 只遍历3万次
for i in range(len(word) - 1):
pairs[pair] += freq # "the"出现10万次,直接加10万
- 选择性合并:每次只处理 20-30%包含目标 pair 的词
优化前
sequences = merge(sequences, best_pair, new_token) # 遍历所有100万序列
优化后
for word, count in word_freqs.items():
if best_pair[0] in word and best_pair[1] in word: # 先过滤
new_word = merge_word(word, best_pair, new_token)
new_word_freqs[new_word] = count
else:
new_word_freqs[word] = count # 不包含的直接复制
- 使用 tuple 代替 list:查找 O(1) vs 遍历 O(n),支持高效去重
优化前
sequences: List[List[str]] # list不可哈希
优化后
word_freqs: Dict[Tuple[str, ...], int] # tuple可做字典key
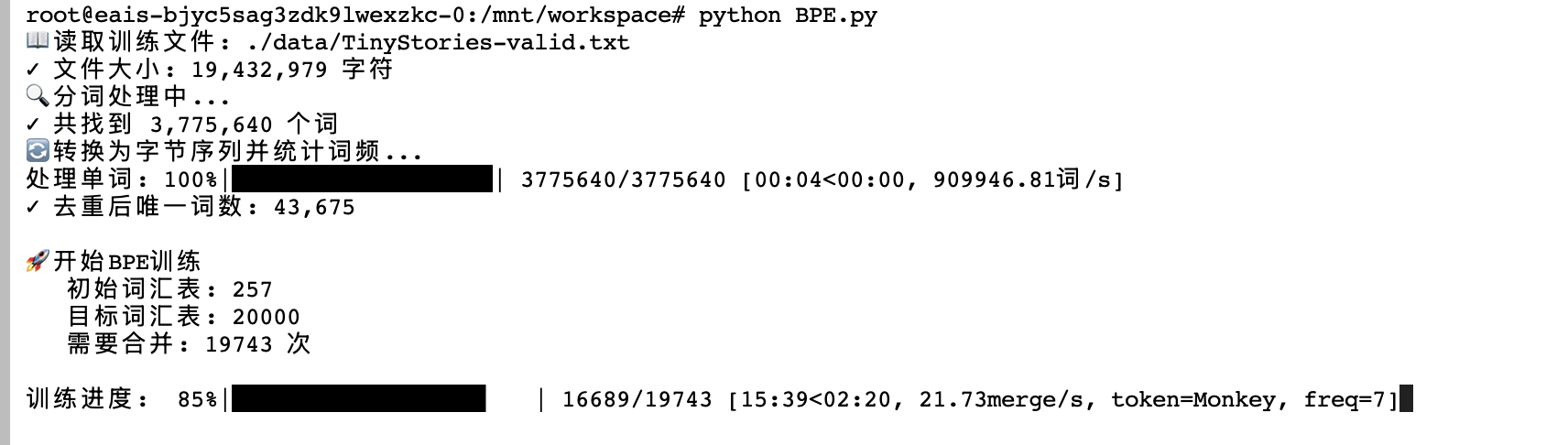
性能对比
| 指标 | 优化前 | 优化后 | 提升 |
|---|---|---|---|
| 速度 | 0.08 merge/s | 10.18 merge/s | 127 倍 |
| 完成时间 | 69 小时 | 32 分钟 | 129 倍 |
| 内存占用 | ~100 万序列 | ~3 万唯一词 | 节省 97% |
| 理论复杂度 | O(M×N×L) | O(M×U×L) | 减少 33 倍 |
其中:M=merge 次数, N=总词数, U=唯一词数, L=平均词长
算法复杂度分析
- 优化前:
- 每次 merge: O(N × L) = 1 千万次操作
- 总计: O(M × N × L) = 2000 亿次操作
- 优化后:
- 每次 merge: O(U × L) = 30 万次操作
- 总计: O(M × U × L) = 60 亿次操作
二次优化
优化前的问题:
- 每次合并后都要重新遍历所有 word_freqs,重新计算所有 pair 的频率
- 时间复杂度:O(vocab_size × total_words × avg_word_length)
- 大量重复计算,效率低下
优化后的方案:
- 只在初始化时统计一次所有 pair 频率 -每次合并只更新受影响的词
- 时间复杂度:O(vocab_size × affected_words × avg_word_length)
预计算 pair 频率表
# 初始化时一次性统计
pair_counts = collections.defaultdict(int)
for word, freq in word_freqs.items():
for i in range(len(word) - 1):
pair = (word[i], word[i + 1])
pair_counts[pair] += freq
# 找出包含best_pair的词(而不是所有词)
affected_words = []
for word, count in word_freqs.items():
has_pair = any(word[i:i+2] == best_pair for i in range(len(word) - 1))
if has_pair:
affected_words.append((word, count))
# 步骤1: 减去旧词的pair频率
for i in range(len(word) - 1):
pair_counts[old_pair] -= count
if pair_counts[old_pair] <= 0:
del pair_counts[old_pair]
# 步骤2: 合并best_pair
new_word = merge_word(word, best_pair, new_token)
# 步骤3: 添加新词的pair频率
for i in range(len(new_word) - 1):
pair_counts[new_pair] += count
# 优化前:
has_pair = any(
word[i] == best_pair[0] and word[i+1] == best_pair[1]
for i in range(len(word) - 1)
)
# 优化后:
has_pair = any(word[i:i+2] == best_pair for i in range(len(word) - 1))