LMDeploy 是一个由上海人工智能实验室开发的高效、友好的大语言模型(LLMs)和视觉-语言模型(VLMs)部署工具箱,功能涵盖了量化、推理和服务。本文将基于 24GB 显卡环境,详细介绍如何使用 LMDeploy 部署通义千问 Qwen2.5-7B-Instruct 模型。
核心特性
高效推理 (Efficient Inference)
- Persistent Batch:实现连续批处理,优化吞吐量
- Blocked K/V Cache:内存高效的缓存管理机制
- 动态拆分和融合:智能的计算图优化
- 张量并行:支持多 GPU 并行推理
- 高效计算核心:优化的 CUDA kernel 实现
可靠量化 (Reliable Quantization)
- 权重量化:支持 4bit/8bit 权重量化
- AWQ 量化:激活感知权重量化技术
- 性能优势:4bit 量化模型推理效率是 FP16 的 2.4 倍
便捷服务 (Convenient Service)
- 请求分发服务:支持多模型、多机、多卡推理服务
- OpenAI 兼容 API:无缝接入现有应用
- 多种部署方式:支持 Docker、Kubernetes 等部署方案
卓越兼容性 (Outstanding Compatibility)
- 多框架支持:TurboMind 引擎和 PyTorch 引擎
- 广泛模型支持:涵盖主流开源大语言模型
- 多平台适配:Linux、Windows、华为昇腾等平台
系统要求
硬件要求
- GPU: 24GB+ 显存(RTX 4090/3090、A10/A100、RTX 6000)
- 内存: 32GB+(推荐 64GB)
- 存储: 30GB+ 可用空间(FP16 模型约 15GB,4bit 量化后约 4GB)
软件要求
- Python: 3.10+
- CUDA: 11.3+ 或 12.x(推荐)
- 操作系统: Linux 或 Windows
性能参考
| GPU 型号 | FP16 推理速度 | 4bit AWQ 推理速度 | 备注 |
|---|---|---|---|
| RTX 4090 | 35-50 tokens/s | 50-80 tokens/s | 4bit 性能提升 |
| RTX 3090 | 28-40 tokens/s | 40-65 tokens/s | 显存占用减半 |
| A10/A100 | 30-60 tokens/s | 45-90 tokens/s | 依据具体配置 |
环境准备
1. 创建 Python 环境
# 创建独立的conda环境
conda create -n lmdeploy python=3.10 -y
conda activate lmdeploy
2. 安装 LMDeploy
# 克隆仓库
git clone https://github.com/InternLM/lmdeploy.git
cd lmdeploy
# 安装依赖并编译
pip install -e .
3. 验证安装
# 检查安装状态
python -c "import lmdeploy; print(lmdeploy.__version__)"
# 查看环境信息
lmdeploy check_env
使用 ModelScope 下载 Qwen2.5-7B-Instruct 模型
关于 Qwen2.5-7B-Instruct 模型:Qwen2.5-7B-Instruct 是阿里巴巴推出的 70 亿参数指令跟随模型,基于 Qwen2.5 架构,在 LMDeploy 中有完整的官方支持。该模型在保持高质量对话能力的同时,对硬件要求适中,非常适合 24GB 显存的部署环境。
# 安装modelscope
pip install modelscope
# 使用命令行下载模型
modelscope download --model qwen/Qwen2.5-7B-Instruct --cache_dir ./models
离线推理部署
1. 基础推理示例
# basic_inference.py
from lmdeploy import pipeline
# 创建推理管道
pipe = pipeline("qwen/Qwen2.5-7B-Instruct")
# 单轮对话
response = pipe(["你好,请介绍一下自己"])
print("回答:", response[0].text)
# 多轮对话
messages = [
{"role": "user", "content": "什么是人工智能?"},
{"role": "assistant", "content": "人工智能(AI)是计算机科学的一个分支..."},
{"role": "user", "content": "它有哪些应用领域?"}
]
response = pipe(messages)
print("回答:", response[0].text)
2. 高级配置示例
# advanced_inference.py
from lmdeploy import pipeline, TurbomindEngineConfig
from lmdeploy.messages import GenerationConfig
# 配置TurboMind引擎(推荐用于24GB显卡)
backend_config = TurbomindEngineConfig(
max_batch_size=32, # 最大批处理大小
enable_prefix_caching=True, # 启用前缀缓存
cache_max_entry_count=0.8, # KV缓存占用显存比例
session_len=8192, # 最大序列长度
tp=1, # 张量并行度(单卡设为1)
)
# 创建推理管道
pipe = pipeline(
'qwen/Qwen2.5-7B-Instruct',
backend_config=backend_config
)
# 生成配置
gen_config = GenerationConfig(
max_new_tokens=2048, # 最大生成token数
top_p=0.8, # nucleus采样参数
top_k=40, # top-k采样参数
temperature=0.7, # 温度参数
repetition_penalty=1.1 # 重复惩罚
)
# 推理测试
prompts = [
"请解释什么是机器学习",
"写一个Python快速排序算法",
"推荐几本人工智能入门书籍"
]
responses = pipe(prompts, gen_config=gen_config)
for i, resp in enumerate(responses):
print(f"问题 {i+1}: {prompts[i]}")
print(f"回答: {resp.text}")
print("-" * 50)
API 服务部署
1. 启动基础 API 服务
# 启动OpenAI兼容的API服务
lmdeploy serve api_server ./models/qwen/Qwen2.5-7B-Instruct \
--server-port 23333 \
--backend turbomind \
--tp 1
2. 高级配置启动
# 完整配置的API服务启动
lmdeploy serve api_server ./models/qwen/Qwen2.5-7B-Instruct \
--server-port 23333 \
--server-name 0.0.0.0 \
--backend turbomind \
--tp 1 \
--max-batch-size 32 \
--cache-max-entry-count 0.8 \
--session-len 8192 \
--enable-prefix-caching \
--log-level INFO
3. 服务配置参数说明
| 参数 | 说明 | 默认值 | 推荐设置 |
|---|---|---|---|
--server-port | API 服务端口 | 23333 | 23333 |
--server-name | 绑定 IP 地址 | 127.0.0.1 | 0.0.0.0 |
--backend | 推理引擎 | auto | turbomind |
--tp | 张量并行度 | 1 | 1(单卡) |
--max-batch-size | 最大批处理 | 128 | 32 |
--cache-max-entry-count | KV 缓存比例 | 0.8 | 0.8 |
--session-len | 最大序列长度 | auto | 8192 |
--enable-prefix-caching | 前缀缓存 | False | True |
4. 客户端调用示例
# client_example.py
from openai import OpenAI
# 创建客户端
client = OpenAI(
api_key='sk-any-key', # 可以是任意字符串
base_url="http://localhost:23333/v1"
)
# 获取模型列表
models = client.models.list()
model_name = models.data[0].id
print(f"可用模型: {model_name}")
# 单轮对话
response = client.chat.completions.create(
model=model_name,
messages=[
{"role": "system", "content": "你是一个有用的AI助手。"},
{"role": "user", "content": "请介绍一下量子计算的基本原理"}
],
temperature=0.7,
max_tokens=1024,
top_p=0.8
)
print("AI回答:", response.choices[0].message.content)
# 流式对话
print("\n流式对话演示:")
stream = client.chat.completions.create(
model=model_name,
messages=[
{"role": "user", "content": "写一首关于春天的诗"}
],
stream=True,
temperature=0.8
)
for chunk in stream:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end='', flush=True)
print()
模型量化部署
1. 4-bit AWQ 量化
# 完整参数的AWQ量化命令
export HF_MODEL=qwen/Qwen2.5-7B-Instruct
export WORK_DIR=./qwen2.5-7b-instruct-4bit
lmdeploy lite auto_awq \
$HF_MODEL \
--calib-dataset 'ptb' \
--calib-samples 128 \
--calib-seqlen 2048 \
--w-bits 4 \
--w-group-size 128 \
--batch-size 1 \
--work-dir $WORK_DIR
# 简化版本(推荐)
lmdeploy lite auto_awq qwen/Qwen2.5-7B-Instruct --work-dir ./qwen2.5-7b-instruct-4bit
# 如果遇到网络连接问题,使用镜像源
export HF_ENDPOINT=https://hf-mirror.com
lmdeploy lite auto_awq qwen/Qwen2.5-7B-Instruct --work-dir ./qwen2.5-7b-instruct-4bit
参数说明:
--calib-dataset: 校准数据集,默认’ptb’(Penn Treebank)--calib-samples: 校准样本数,默认 128--calib-seqlen: 序列长度,默认 2048--w-bits: 权重位数,默认 4--w-group-size: 分组大小,默认 128--batch-size: 批处理大小,默认 1--work-dir: 输出目录,建议包含模型名称
量化成功标志:
当看到以下输出时,表示量化成功完成:
2. 部署量化模型
# quantized_inference.py
from lmdeploy import pipeline, TurbomindEngineConfig
# 使用量化模型的配置
backend_config = TurbomindEngineConfig(model_format='awq')
# 创建量化模型推理管道(使用本地量化模型路径)
pipe = pipeline(
'./qwen2.5-7b-instruct-4bit', # 本地量化模型路径
backend_config=backend_config
)
# 性能测试
import time
test_prompts = ["解释什么是大语言模型"] * 10
start_time = time.time()
responses = pipe(test_prompts)
end_time = time.time()
print(f"量化模型推理时间: {end_time - start_time:.2f}s")
print(f"平均每个请求: {(end_time - start_time) / 10:.2f}s")
# 单次对话测试
response = pipe(["你好,请介绍一下自己"])
print("量化模型回答:", response[0].text)
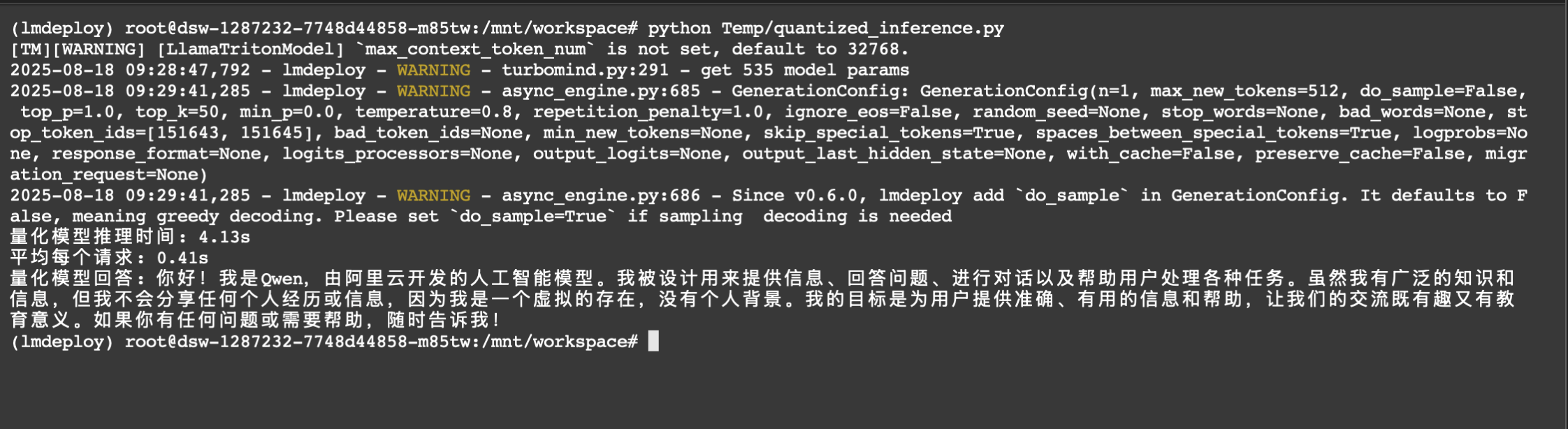
推理配置说明:
- 使用本地量化模型路径
./qwen2.5-7b-instruct-4bit - 必须指定
model_format='awq'才能正确加载 AWQ 量化模型 - 量化模型相比 FP16 模型可显著降低显存占用和推理时间
量化验证:
# 启动量化模型API服务
lmdeploy serve api_server ./qwen2.5-7b-instruct-4bit \
--backend turbomind \
--model-format awq \
--server-port 23333
# 测试API服务(另开终端)
curl -X POST http://localhost:23333/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "./qwen2.5-7b-instruct-4bit",
"messages": [{"role": "user", "content": "你好,请介绍一下自己"}],
"temperature": 0.7,
"max_tokens": 100
}'
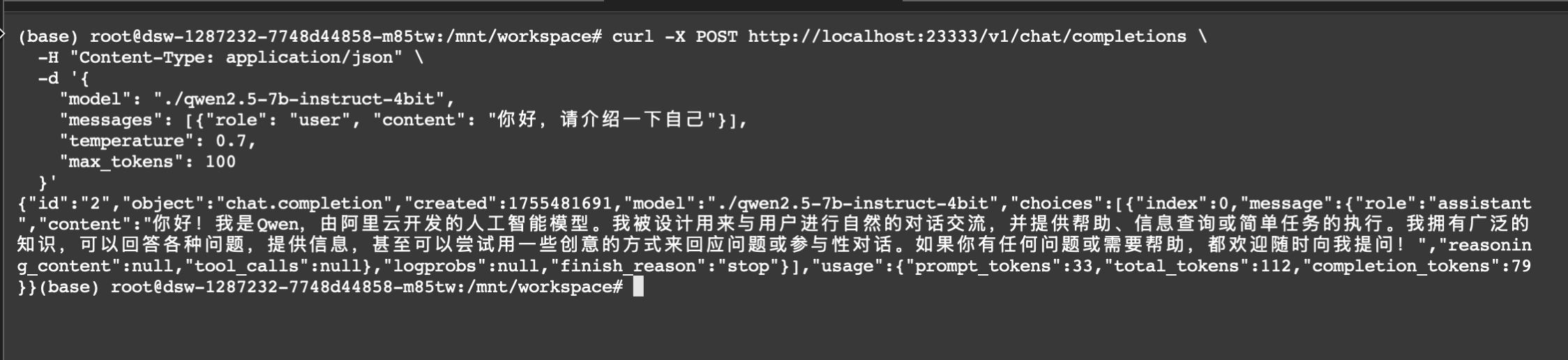
注意事项:
- 量化过程需要较长时间,建议使用默认参数
- 如果量化精度有损,可开启
--search-scale重新量化 - 显存不足时可减小
--calib-seqlen或设置--batch-size 1 - 量化后的 4bit 模型推理速度比 FP16 提升约 2.4 倍
常见问题与解决方案
1. 显存不足 (OOM)
问题现象:
[TM][ERROR] CUDA runtime error: out of memory
已中止
解决方案:
# 量化模型内存优化启动(推荐)
lmdeploy chat ./qwen2.5-7b-instruct-4bit --model-format awq \
--cache-max-entry-count 0.3 \
--session-len 2048 \
--max-batch-size 1
# API 服务内存优化启动
lmdeploy serve api_server ./qwen2.5-7b-instruct-4bit \
--backend turbomind \
--model-format awq \
--cache-max-entry-count 0.3 \
--session-len 2048 \
--max-batch-size 1 \
--server-port 23333
2. 量化失败
问题现象:
ConnectionError: Couldn't reach 'ptb_text_only' on the Hub
解决方案:
# 使用离线数据集(推荐)
lmdeploy lite auto_awq ./models/qwen/Qwen2.5-7B-Instruct \
--calib-dataset 'random' \
--calib-samples 128 \
--work-dir ./qwen2.5-7b-instruct-4bit
# 或使用镜像源
export HF_ENDPOINT=https://hf-mirror.com
lmdeploy lite auto_awq ./models/qwen/Qwen2.5-7B-Instruct \
--calib-dataset 'c4' \
--work-dir ./qwen2.5-7b-instruct-4bit
3. 服务启动失败
常见错误:
Address already in use: 23333
解决方案:
# 检查并释放端口
lsof -i :23333
kill -9 <PID>
# 或使用其他端口
lmdeploy serve api_server ./qwen2.5-7b-instruct-4bit \
--model-format awq --server-port 23334
总结
LMDeploy 作为一个高效的大语言模型部署工具,在 24GB+ 显卡环境下能够很好地支持 Qwen2.5-7B-Instruct 模型的部署和推理。LMDeploy 降低了大语言模型部署的技术门槛,使得开发者可以更容易地将先进的 AI 能力集成到实际应用中,是构建 AI 应用的理想选择。