OpenCompass 是一个由上海人工智能实验室开发的开放平台,用于评估大语言模型(LLM)的性能。它提供了全面的评测体系,支持多种主流模型和数据集,可以与 LMDeploy 等推理框架无缝集成,为模型性能评估提供标准化的解决方案。
核心特性
全面评测体系 (Comprehensive Evaluation)
- 多维度评测:涵盖知识、推理、理解、安全等多个维度
- 标准化流程:配置 → 推理 → 评估 → 可视化的完整评测链路
- 丰富数据集:支持 100+ 主流评测数据集
- 客观与主观评测:支持自动评分和人工评判
高效推理支持 (Efficient Inference)
- 多推理引擎:支持 LMDeploy、vLLM、HuggingFace 等多种推理后端
- 并行加速:支持多 GPU 并行推理,大幅提升评测效率
- 内存优化:支持量化模型评测,降低硬件要求
- 批处理优化:智能批处理策略,最大化硬件利用率
易用性与扩展性 (Usability & Extensibility)
- 简单配置:支持命令行和配置文件两种使用方式
- 模块化设计:易于添加新模型、新数据集、新评测指标
- 结果可视化:自动生成评测报告和排行榜
- API 兼容:支持 OpenAI API 格式的模型评测
系统要求
- Python: 3.10+
- GPU: 6GB+ 显存(推荐 24GB+)
- 内存: 16GB+(推荐 32GB+)
- 存储: 50GB+ 可用空间
- CUDA: 11.3+ 或 12.x
环境准备
1. 创建 Python 环境
# 创建独立的conda环境
conda create --name opencompass python=3.10 -y
conda activate opencompass
2. 安装 OpenCompass
# 克隆仓库
git clone https://github.com/open-compass/opencompass.git
cd opencompass
# 安装基础依赖
pip install -e .
# 安装 LMDeploy 支持
pip install lmdeploy
# 安装额外依赖(可选)
pip install protobuf
pip install human-eval
3. 数据集准备
自动下载(推荐)
OpenCompass 支持在首次评测时自动下载所需数据集,这是最简单的方式:
# 设置环境变量使用 ModelScope 源(解决网络问题)
export DATASET_SOURCE=ModelScope
# 设置 HuggingFace 镜像源
export HF_ENDPOINT=https://hf-mirror.com
# 首次运行评测时会自动下载数据集
python run.py \
--datasets demo_gsm8k_chat_gen demo_math_chat_gen \
--hf-type chat \
--hf-path qwen/Qwen2.5-7B-Instruct \
--debug
# 或者使用本地模型路径
python run.py \
--datasets demo_gsm8k_chat_gen demo_math_chat_gen \
--hf-type chat \
--hf-path ./models/qwen/Qwen2.5-7B-Instruct \
--debug
# 中文评测示例
python run.py \
--datasets demo_cmmlu_chat_gen \
--hf-type chat \
--hf-path ./models/qwen/Qwen2.5-7B-Instruct \
--debug
# 查看可用的demo数据集配置
python tools/list_configs.py | grep demo
# 可用的demo数据集配置:
# - demo_gsm8k_chat_gen: 数学推理(对话模式)
# - demo_math_chat_gen: 数学问题(对话模式)
# - demo_cmmlu_chat_gen: 中文多任务理解(对话模式)
# - demo_gsm8k_base_gen: 数学推理(基座模式)
# - demo_math_base_gen: 数学问题(基座模式)
# - demo_cmmlu_base_ppl: 中文理解(困惑度模式)
自动下载的优势:
- 按需下载,只获取当前评测所需的数据集
- 自动处理数据集格式转换
- 支持断点续传,网络中断后可继续下载
- 自动验证数据完整性

与 LMDeploy 集成
基于已经部署的千问 2.5-7B LMDeploy 服务,我们提供三种集成方式:直接模型评测、量化模型评测和 API 服务评测。
1. 基础集成配置
创建配置文件 configs/eval_qwen25_lmdeploy.py:
# eval_qwen25_lmdeploy.py
from mmengine.config import read_base
# 导入数据集配置
with read_base():
# 数学推理数据集
from .datasets.gsm8k.gsm8k_0shot_v2_gen_a58960 import gsm8k_datasets
from .datasets.math.math_0shot_gen_393424 import math_datasets
# 语言理解数据集
from .datasets.mmlu.mmlu_gen_a484b3 import mmlu_datasets
from .datasets.ceval.ceval_gen_5f30c7 import ceval_datasets
# 推理能力数据集
from .datasets.hellaswag.hellaswag_10shot_ppl_59c85e import hellaswag_datasets
from .datasets.arc.arc_gen_2ef631 import ARC_datasets
# 结果汇总配置
from .summarizers.medium import summarizer
# 合并所有数据集
datasets = sum((v for k, v in locals().items() if k.endswith('_datasets')), [])
# 配置 LMDeploy 推理引擎
from opencompass.models import TurboMindModelwithChatTemplate
models = [
dict(
type=TurboMindModelwithChatTemplate,
abbr='qwen25-7b-instruct-lmdeploy',
# 模型路径(支持 HuggingFace Hub 或本地路径)
path='qwen/Qwen2.5-7B-Instruct',
# 推理后端:turbomind(推荐)或 pytorch
backend='turbomind',
# TurboMind 引擎配置
engine_config=dict(
tp=1, # 张量并行度(单卡设为1)
max_batch_size=32, # 最大批处理大小
cache_max_entry_count=0.8, # KV缓存占用显存比例
enable_prefix_caching=True, # 启用前缀缓存
session_len=8192, # 最大上下文长度
),
# 生成配置
gen_config=dict(
max_new_tokens=1024, # 最大生成token数
do_sample=False, # 是否采样
temperature=0.0, # 温度参数
top_p=1.0, # nucleus采样参数
),
# 序列长度配置
max_seq_len=8192,
max_out_len=1024,
# 批处理配置
batch_size=32,
# 运行配置
run_cfg=dict(num_gpus=1),
)
]
运行配置文件:
# 创建并运行LMDeploy集成配置
python run.py configs/eval_qwen25_lmdeploy.py -w outputs/qwen25_lmdeploy_eval
# 使用HuggingFace模型运行
python run.py \
--datasets demo_gsm8k_chat_gen demo_math_chat_gen \
--hf-type chat \
--hf-path ./models/qwen/Qwen2.5-7B-Instruct \
--debug \
-w outputs/hf_qwen25_eval
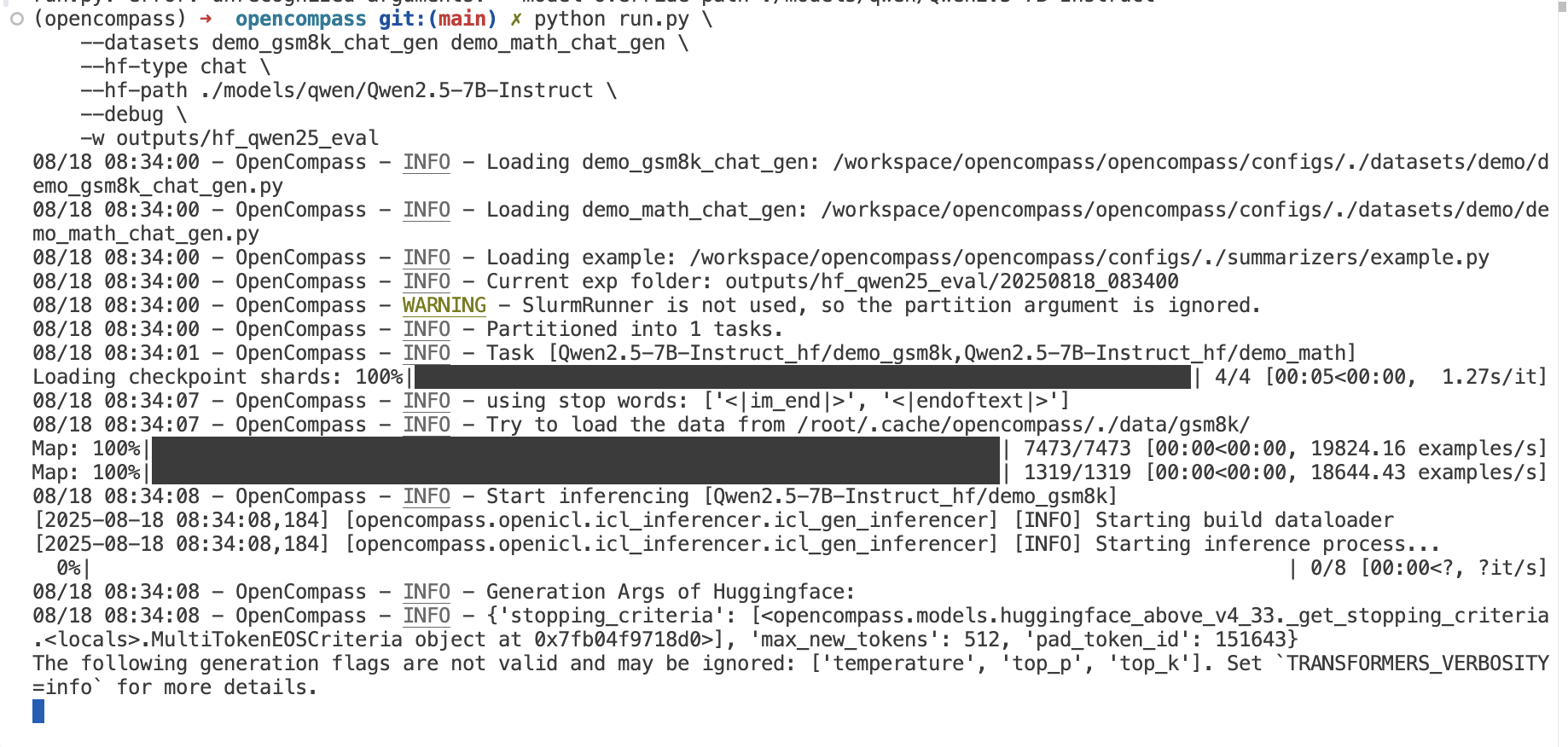
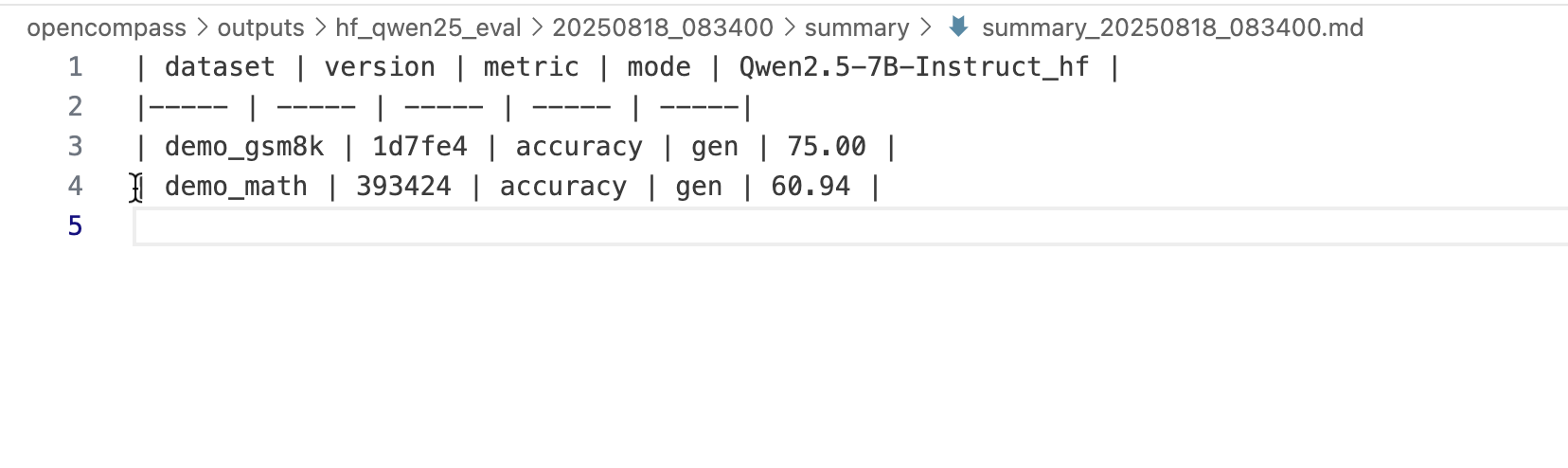
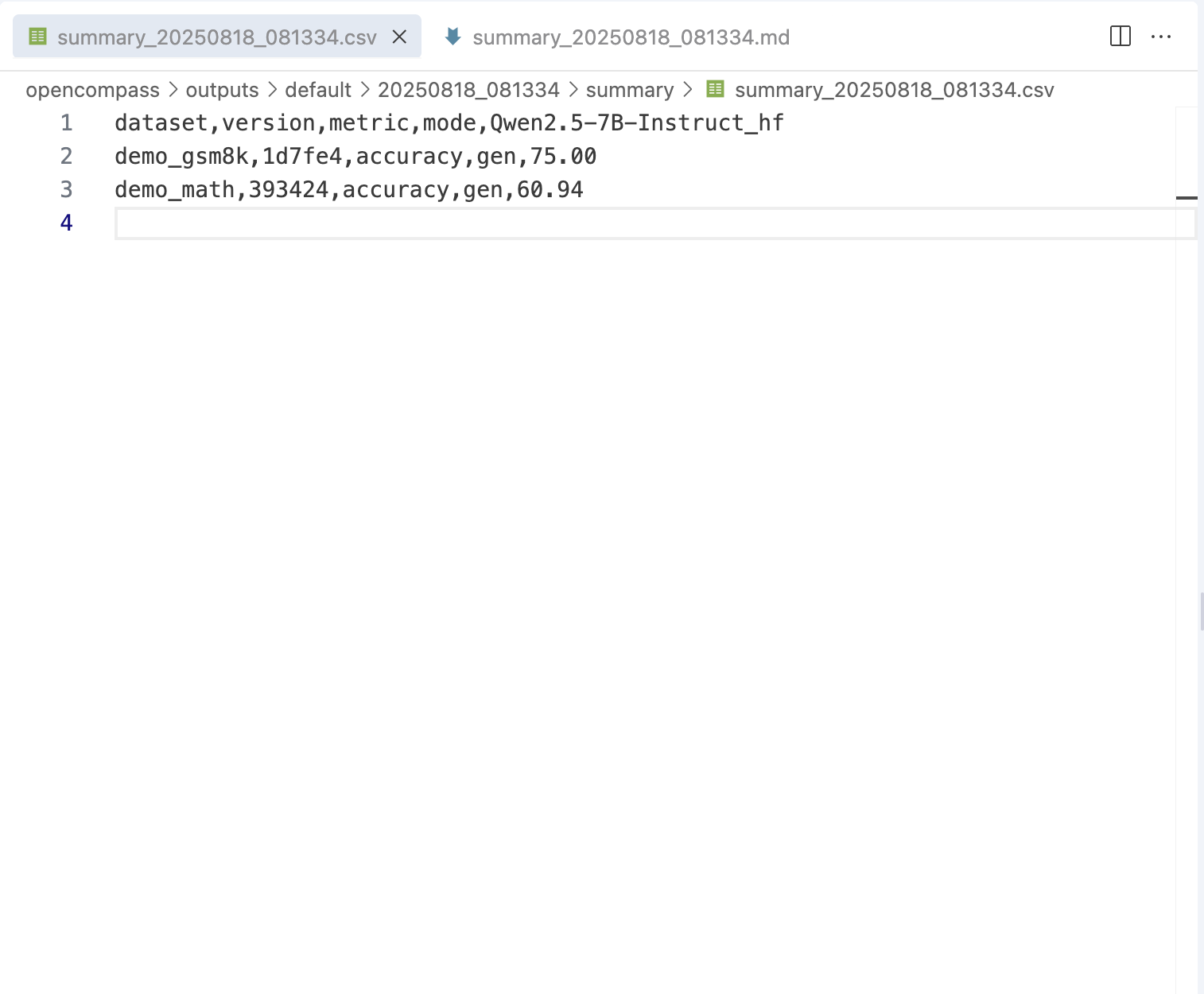
2. 数学推理能力评测
创建专门的数学评测配置 configs/eval_math_qwen25.py,并使用第三方数据集 GSM8K 进行验证。
# configs/eval_math_qwen25.py
from mmengine.config import read_base
from opencompass.models import TurboMindModelwithChatTemplate
# 1. 使用 read_base 导入 OpenCompass 内置的 gsm8k 数据集配置
with read_base():
from .datasets.gsm8k.gsm8k_gen import gsm8k_datasets
# 2. 模型配置
models = [
dict(
type=TurboMindModelwithChatTemplate,
abbr='qwen25-7b-instruct-math',
path='qwen/Qwen2.5-7B-Instruct',
backend='turbomind',
engine_config=dict(tp=1, max_batch_size=16),
gen_config=dict(
max_new_tokens=2048,
do_sample=False,
temperature=0.0,
),
max_seq_len=8192,
max_out_len=2048,
batch_size=16,
run_cfg=dict(num_gpus=1),
)
]
# 3. 将数据集列表指向导入的配置
datasets = gsm8k_datasets
# 4. 工作目录
work_dir = 'outputs/math_eval'
运行说明:
设置下载源 (重要): 在运行评测前,请在终端执行以下命令,以确保能顺利下载数据集。
export HF_ENDPOINT=https://hf-mirror.com export DATASET_SOURCE=ModelScope执行评测: 将上述 Python 代码保存为
configs/eval_math_qwen25.py文件,然后运行:python run.py configs/eval_math_qwen25.py -w outputs/math_evalOpenCompass 在首次运行时会自动下载
gsm8k数据集。如果已经下载过,它会直接使用缓存。预先下载数据集 (可选): 如果你希望提前下载,可以运行以下 Python 命令:
python -c "from datasets import load_dataset; load_dataset('gsm8k', 'main')"
3. 中文能力评测
创建中文评测配置 configs/eval_chinese_qwen25.py:
# configs/eval_chinese_qwen25.py
from mmengine.config import read_base
with read_base():
# 中文理解数据集
from .datasets.ceval.ceval_gen_5f30c7 import ceval_datasets
from .datasets.cmmlu.cmmlu_gen_c13365 import cmmlu_datasets
# 中文推理数据集
from .datasets.chid.chid_gen_2b72a4 import chid_datasets
from .datasets.c3.c3_gen_4b127c import c3_datasets
# 结果汇总
from .summarizers.chinese import summarizer
datasets = ceval_datasets + cmmlu_datasets + chid_datasets + c3_datasets
from opencompass.models import TurboMindModelwithChatTemplate
models = [
dict(
type=TurboMindModelwithChatTemplate,
abbr='qwen25-7b-instruct-chinese',
path='qwen/Qwen2.5-7B-Instruct',
backend='turbomind',
engine_config=dict(tp=1, max_batch_size=32),
gen_config=dict(max_new_tokens=1024, do_sample=False),
max_seq_len=8192,
max_out_len=1024,
batch_size=32,
run_cfg=dict(num_gpus=1),
)
]
4. 安全性评测
创建安全性评测配置 configs/eval_safety_qwen25.py:
# configs/eval_safety_qwen25.py
from mmengine.config import read_base
with read_base():
# 安全性数据集
from .datasets.safetybench.safetybench_gen import safetybench_datasets
from .datasets.advglue.advglue_gen import advglue_datasets
from .summarizers.safety import summarizer
datasets = safetybench_datasets + advglue_datasets
from opencompass.models import TurboMindModelwithChatTemplate
models = [
dict(
type=TurboMindModelwithChatTemplate,
abbr='qwen25-7b-instruct-safety',
path='qwen/Qwen2.5-7B-Instruct',
backend='turbomind',
engine_config=dict(tp=1, max_batch_size=16),
gen_config=dict(
max_new_tokens=512,
do_sample=True, # 安全性测试使用采样
temperature=0.7,
top_p=0.9,
),
max_seq_len=4096,
max_out_len=512,
batch_size=16,
run_cfg=dict(num_gpus=1),
)
]
总结
OpenCompass 作为专业的大语言模型评测平台,与 LMDeploy 的深度集成为模型性能评估提供了强有力的支撑。通过本文的详细介绍,您可以:
- 快速部署:轻松搭建完整的评测环境
- 灵活配置:根据需求定制评测方案
- 高效评测:利用 LMDeploy 加速获得准确结果
- 深入分析:全面了解模型在各个维度的表现
OpenCompass 降低了模型评测的技术门槛,使得研究者和开发者能够更容易地进行标准化的模型性能评估,为 AI 模型的选择和优化提供科学依据。